Large Language Models
Our laboratory's research is dedicated to advancing the development of large models in dynamic real-world scenarios, with a particular emphasis on continual learning (CL) , parameter-efficient fine-tuning (PEFT) and reinforced fine-tuning (RFT). The core areas of our work include formulating strategies to mitigate the catastrophic forgetting problem, which is the tendency of LLMs to lose previously acquired knowledge when learning new tasks. We also aim to enhance the adaptability of models across various domains such as natural language understanding, code generation, and mathematical reasoning. Additionally, we address challenges related to high computational costs, parameter interference, and data privacy risks.
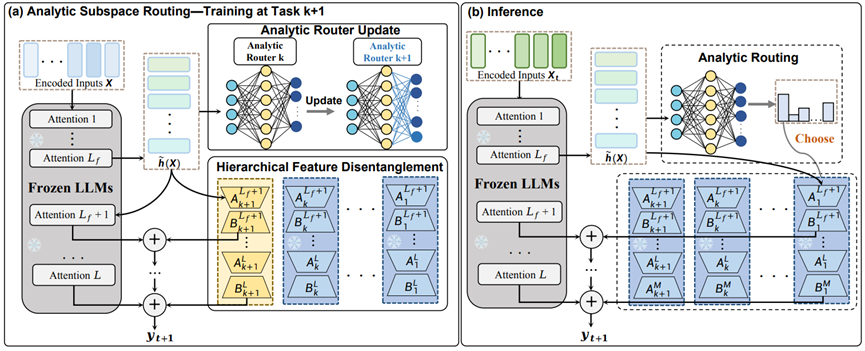
This paper addresses the catastrophic forgetting problem in the continual learning of large language models (LLMs) and the limitations of existing methods, such as those involving replay (leading to high costs) or single parameter modules (resulting in task interference or insufficient capacity). We propose the Analytical Subspace Routing (ASR) method, which creates independent low-rank adapters (LoRA) for each new task within the deep feature space. A dynamic router, trained based on Recursive Least Squares (RLS), is employed. This router analyzes input features to automatically select the most appropriate task-specific LoRA module for inference. Furthermore, it can incrementally update via auto-correlation and cross-correlation matrices without requiring historical data, theoretically guaranteeing zero forgetting.