We have 3 papers accepted by ICML 2025!
We have three papers are accepted by the 42nd International Conference on Machine Learning (ICML’2025). Two papers contribute to the continual learning, addressing the problem of multi-label class incremental learning and dynamic analytic learning for evolving backbone in continual learning respectively. The other paper focuses on the large models, contributing to the watermarked image understanding via multi-modal LLMs. Detailed information about each publication is provided below.
Paper 1: L3A: Label-Augmented Analytic Adaptation for Multi-Label Class Incremental Learning
Authors: Xiang Zhang, Run He, Chen Jiao, Di Fang, Ming Li, Ziqian Zeng, Cen Chen, Huiping Zhuang
Abstract:
Class-incremental learning (CIL) enables models to learn new classes continually without forgetting previously acquired knowledge. Multi-label CIL (MLCIL) extends CIL to a real-world scenario where each sample may belong to multiple classes, introducing several challenges: label absence, which leads to incomplete historical information due to missing labels, and class imbalance, which results in the model bias toward majority classes. To address these challenges, we propose Label-Augmented Analytic Adaptation (L3A), an exemplar-free approach without storing past samples. L3A integrates two key modules. The pseudo-label (PL) module implements label augmentation by generating pseudo-labels for current phase samples, addressing the label absence problem. The weighted analytic classifier (WAC) derives a closed-form solution for neural networks. It introduces sample-specific weights to adaptively balance the class contribution and mitigate class imbalance. Experiments on MS-COCO and PASCAL VOC datasets demonstrate that L3A outperforms existing methods in MLCIL tasks.
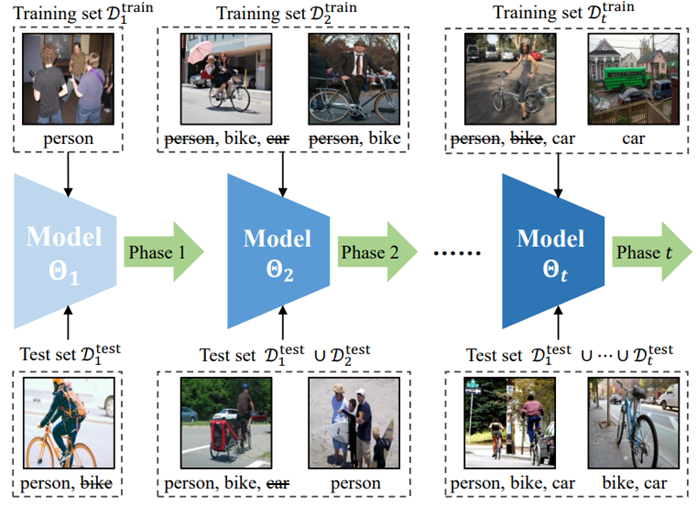
Formulation of multi-label CIL
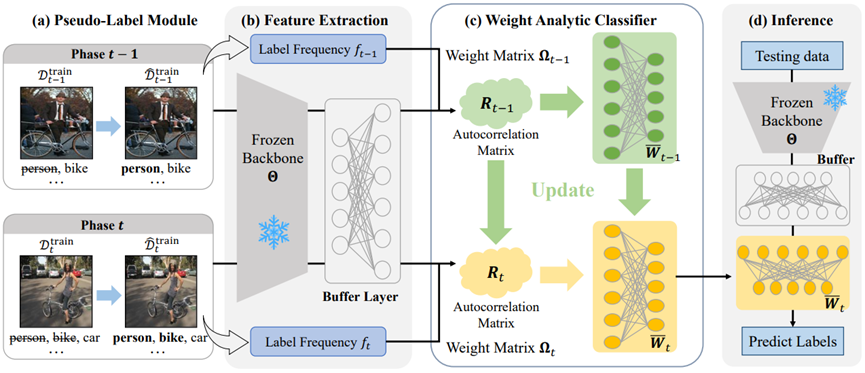
Framework of the proposed L3A
Paper: [To be added]
Code: https://github.com/scut-zx/L3A
Paper 2: Semantic Shift Estimation via Dual-Projection and Classifier Reconstruction for Exemplar-Free Class-Incremental Learning
Authors: Run He, Di Fang, Yicheng Xu, Yawen Cui, Ming Li, Cen Chen, Ziqian Zeng, Huiping Zhuang
Abstract:
Exemplar-Free Class-Incremental Learning (EFCIL) aims to sequentially learn from distinct categories without retaining exemplars but easily suffers from catastrophic forgetting of learned knowledge. While existing EFCIL methods leverage knowledge distillation to alleviate forgetting, they still face two critical challenges: semantic shift and decision bias. Specifically, the embeddings of old tasks shift in the embedding space after learning new tasks, and the classifier becomes biased towards new tasks due to training solely with new data, hindering the balance between old and new knowledge. To address these issues, we propose the Dual-Projection Shift Estimation and Classifier Reconstruction (DPCR) approach for EFCIL. DPCR effectively estimates semantic shift through a dual-projection, which combines a learnable transformation with a row-space projection to capture both task-wise and category-wise shifts. Furthermore, to mitigate decision bias, DPCR employs ridge regression to reformulate a classifier reconstruction process. This reconstruction exploits previous in covariance and prototype of each class after calibration with estimated shift, thereby reducing decision bias. Extensive experiments demonstrate that, on various datasets, DPCR effectively balances old and new tasks, outperforming state-of-the-art EFCIL methods.
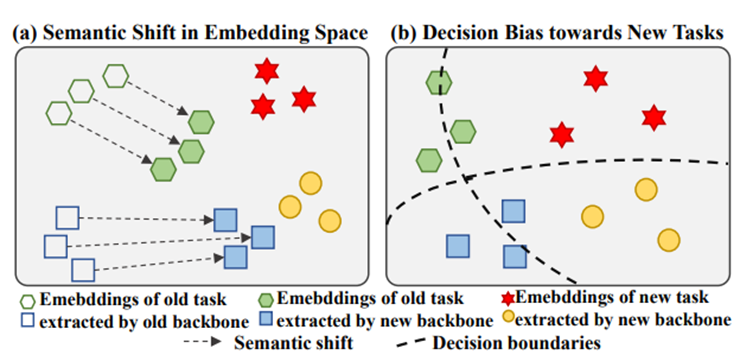
The issue of semantic shift and decision bias in CIL
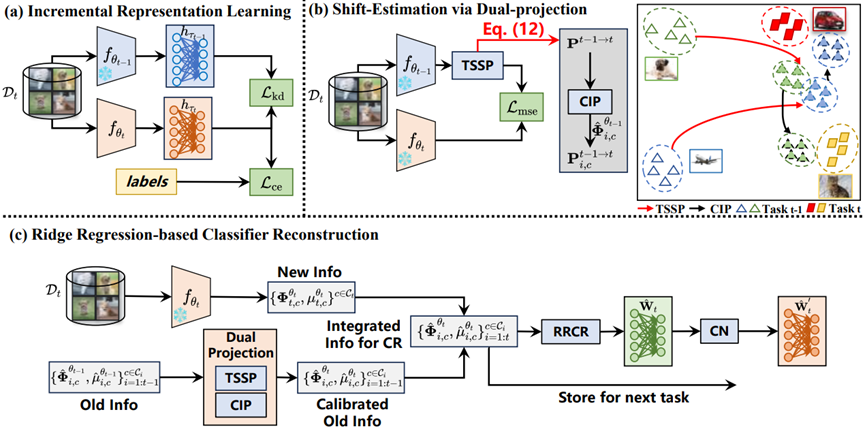
Framework of the proposed DPCR
Paper: https://arxiv.org/abs/2503.05423
Code: https://github.com/RHe502/ICML25-DPCR
Paper 3: WMarkGPT: Watermarked Image Understanding via Multi-modal Large Language Models
Authors: Songbai Tan, Xuerui Qiu, Yao Shu, Gang Xu, Linrui Xu, Xiangyu Xu, Huiping Zhuang, Ming Li, Fei Yu
Abstract:
Invisible watermarking is widely used to protect digital images from unauthorized use. Accurate assessment of watermarking efficacy is crucial for advancing algorithmic development. However, existing statistical metrics, such as PSNR, rely on access to original images, which are often unavailable in text-driven generative watermarking and fail to capture critical aspects of watermarking, particularly visibility. More importantly, these metrics fail to account for potential corruption of image content. To address these limitations, we propose WMarkGPT, the first multimodal large language model (MLLM) specifically designed for comprehensive watermarked image understanding, without accessing original images. WMarkGPT not only predicts watermark visibility but also generates detailed textual descriptions of its location, content, and impact on image semantics, enabling a more nuanced interpretation of watermarked images. Tackling the challenge of precise location description and understanding images with vastly different content, we construct three visual question-answering (VQA) datasets: an object location-aware dataset, a synthetic watermarking dataset, and a real watermarking dataset. We introduce a meticulously designed three-stage learning pipeline to progressively equip WMarkGPT with the necessary abilities. Extensive experiments on synthetic and real watermarking QA datasets demonstrate that WMarkGPT outperforms existing MLLMs, achieving significant improvements in visibility prediction and content description.
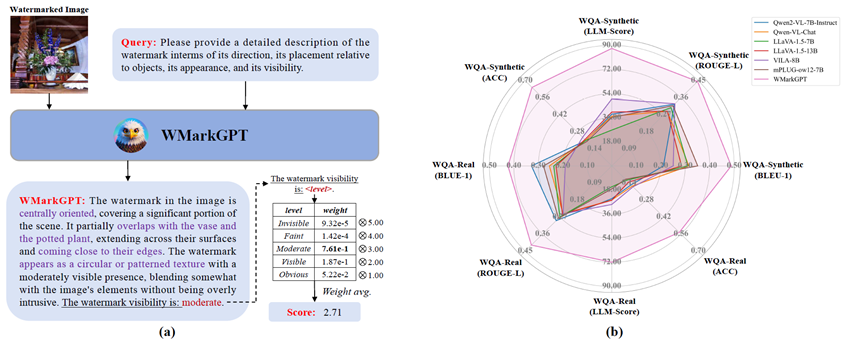
Introduction to WMarkGPT and Comparison with SOTAs
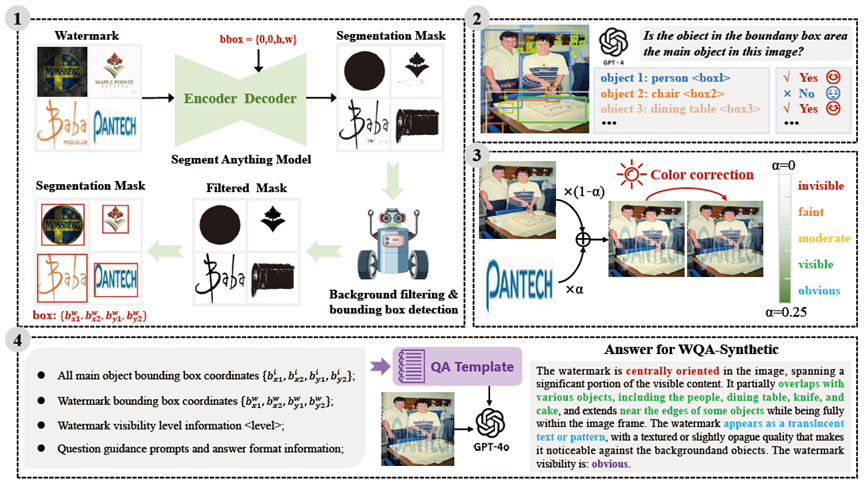
Illustration of WQA-Synthetic semi-automatic annotation pipeline
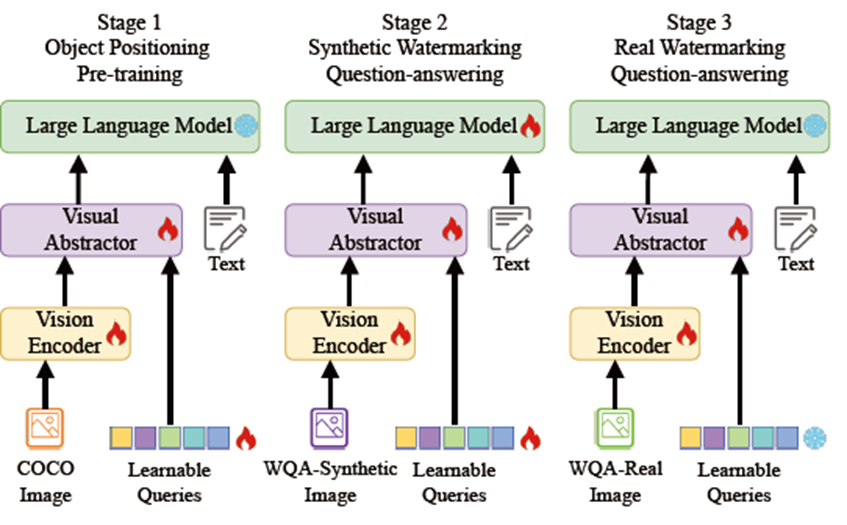
Model architecture and the progressive learning paradigm of WMarkGPT
Paper: [To be added]
Code: https://github.com/TanSongBai/WMarkGPT