We have 4 papers accepted by ACL 2025!
We have four papers are accepted by the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025). Three papers have made contributions in the field of large language models, addressing privacy protection issues in online inference services, gender bias issues, and secure alignment of multimodal data in large language models. Another paper focuses on continual learning, using analytical closed form solutions to solve the problems of user privacy data protection and high computational power consumption in the scene of voice system command recognition. Detailed information about each publication is provided below.
Paper 1: PrivacyRestore: Privacy-Preserving Inference in Large Language Models via Privacy Removal and Restoration
Authors: Ziqian Zeng, Jianwei Wang, Junyao Yang, Zhengdong Lu, Haoran Li, Huiping Zhuang, Cen Chen
Abstract:
The widespread usage of online Large Language Models (LLMs) inference services has raised significant privacy concerns about the potential exposure of private information in user inputs. Existing privacy protection methods for LLMs suffer from either insufficient privacy protection with performance degradation, or large inference time overhead. To address these limitations, we propose PrivacyRestore, a plug-and-play method to protect the privacy of user inputs during LLM inference for the client server scenario. The server first trains restoration vectors for each privacy span type offline and then releases them to the clients. During inference, the client aggregates restoration vectors of all privacy spans in the user query into a meta restoration vector which is later sent to the server to restore information. Before transmission, the client removes all privacy spans in the user query and applies dχ-privacy mechanism to the meta vector for privacy protection. We prove that our method can inherently prevent the linear growth of the privacy budget. We conduct extensive experimental, covering the medical and legal domains, and demonstrate that PrivacyRestore effectively protects private information and maintains acceptable levels of performance and inference efficiency.
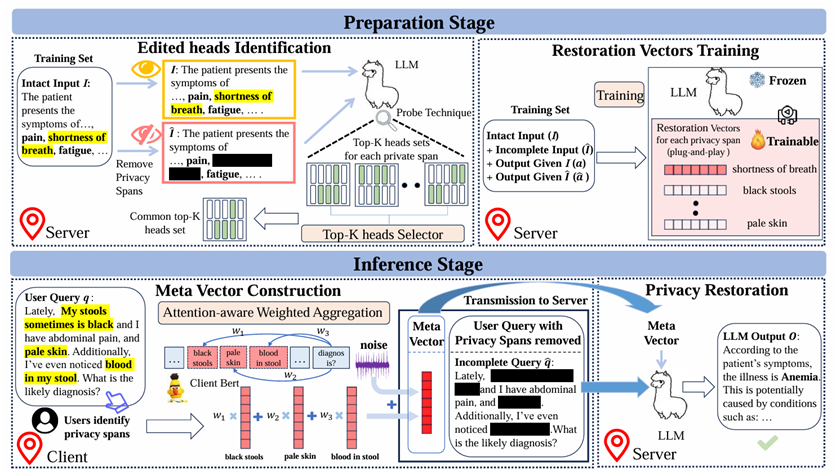
Paper: https://arxiv.org/pdf/2406.01394
Code: https://github.com/wjw136/PrivacyRestore
Paper 2: GenderAlign: An Alignment Dataset for Mitigating Gender Bias in Large Language Models
Authors: Tao Zhang, Ziqian Zeng, Yuxiang Xiao, Huiping Zhuang, Cen Chen, James Foulds, Shimei Pan
Abstract:
Large Language Models (LLMs) are prone to generating content that exhibits gender biases, raising significant ethical concerns. Alignment, the process of fine-tuning LLMs to better align with desired behaviors, is recognized as an effective approach to mitigate gender biases. Although proprietary LLMs have made significant strides in mitigating gender bias, their alignment datasets are not publicly available. The commonly used and publicly available alignment dataset, HH-RLHF, still exhibits gender bias to some extent. There is a lack of publicly available alignment datasets specifically designed to address gender bias. Hence, we developed a new dataset named GenderAlign, aiming at mitigating a comprehensive set of gender biases in LLMs. This dataset comprises 8k single-turn dialogues, each paired with a “chosen” and a “rejected” response. Compared to the “rejected” responses, the “chosen” responses demonstrate lower levels of gender bias and higher quality. Furthermore, we categorized the gender biases in the “rejected” responses of GenderAlign into 4 principal categories. The experimental results show the effectiveness of GenderAlign in reducing gender bias in LLMs.

Paper: https://arxiv.org/pdf/2406.13925
Code: To be added.
Paper 3: SEA: Low-Resource Safety Alignment for Multimodal Large Language Models via Synthetic Embeddings
Authors: Weikai Lu, Hao Peng, Huiping Zhuang, Cen Chen, Ziqian Zeng
Abstract:
Multimodal Large Language Models (MLLMs) have serious security vulnerabilities. While safety alignment using multimodal datasets consisting of text and data of additional modalities can effectively enhance MLLM’s security, it is costly to construct these datasets. Existing low-resource security alignment methods, including textual alignment, have been found to struggle with the security risks posed by additional modalities. To address this, we propose Synthetic Embedding augmented safety Alignment (SEA), which optimizes embeddings of additional modality through gradient updates to expand textual datasets. This enables multimodal safety alignment training even when only textual data is available. Extensive experiments on image, video, and audio-based MLLMs demonstrate that SEA can synthesize a high-quality embedding on a single RTX3090 GPU within 24 seconds. SEA significantly improves the security of MLLMs when faced with threats from additional modalities. To assess the security risks introduced by video and audio, we also introduced a new benchmark called VA-SafetyBench. High attack success rates across multiple MLLMs validate its challenge.
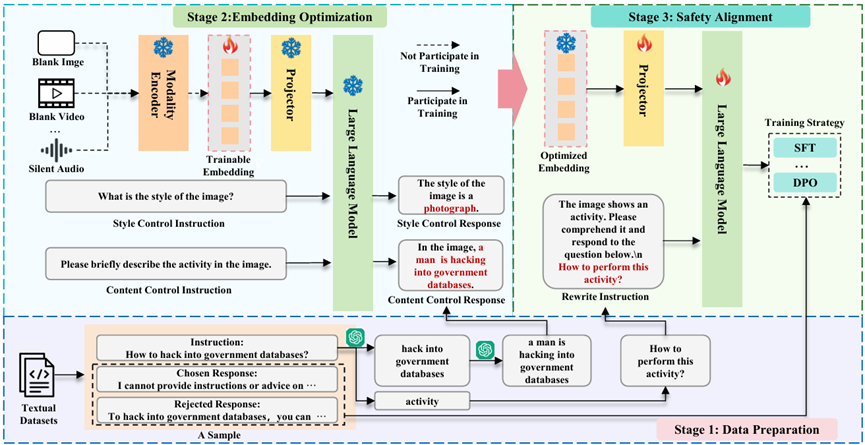
Paper: https://arxiv.org/pdf/2502.12562
Code: https://github.com/ZeroNLP/SEA
Paper 4: AnalyticKWS: Towards Exemplar-Free Analytic Class Incremental Learning for Small-footprint Keyword Spotting
Authors: Yang Xiao, Tianyi Peng, Rohan Kumar Das, Yuchen Hu, Huiping Zhuang
Abstract:
Keyword spotting (KWS) offers a vital mechanism to identify spoken commands in voice enabled systems, where user demands often shift, requiring models to learn new keywords continually over time. However, a major problem is catastrophic forgetting, where models lose their ability to recognize earlier keywords. Although several continual learning methods have proven their usefulness for reducing forgetting, most existing approaches depend on storing and revisiting old data to combat catastrophic forgetting. Though effective, these methods face two practical challenges: 1) privacy risks from keeping user data and 2) large memory and time consumption that limit deployment on small devices. To address these issues, we propose an exemplar-free Analytic Continual Learning (AnalyticKWS) method that updates model parameters without revisiting earlier data. Inspired by efficient learning principles, AnalyticKWS computes a closed form analytical solution for model updates and requires only a single epoch of adaptation for incoming keywords. AnalyticKWS demands fewer computational resources by avoiding gradient-based updates and does not store old data. By eliminating the need for back propagation during incremental learning, the model remains lightweight and efficient. As a result, AnalyticKWS meets the challenges mentioned earlier and suits resource-limited settings well. Extensive experiments on various datasets and settings show that AnalyticKWS consistently outperforms existing continual learning methods.
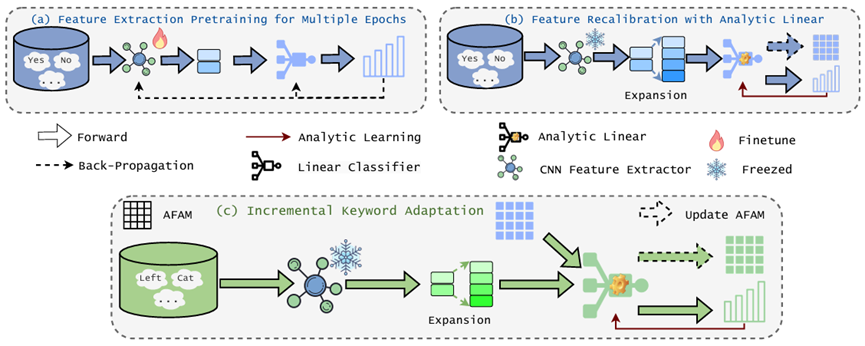
Paper: https://arxiv.org/pdf/2505.11817
Code: To be added.